Résumé de la session
Introduction aux mégadonnées en sciences sociales
Structure du cours
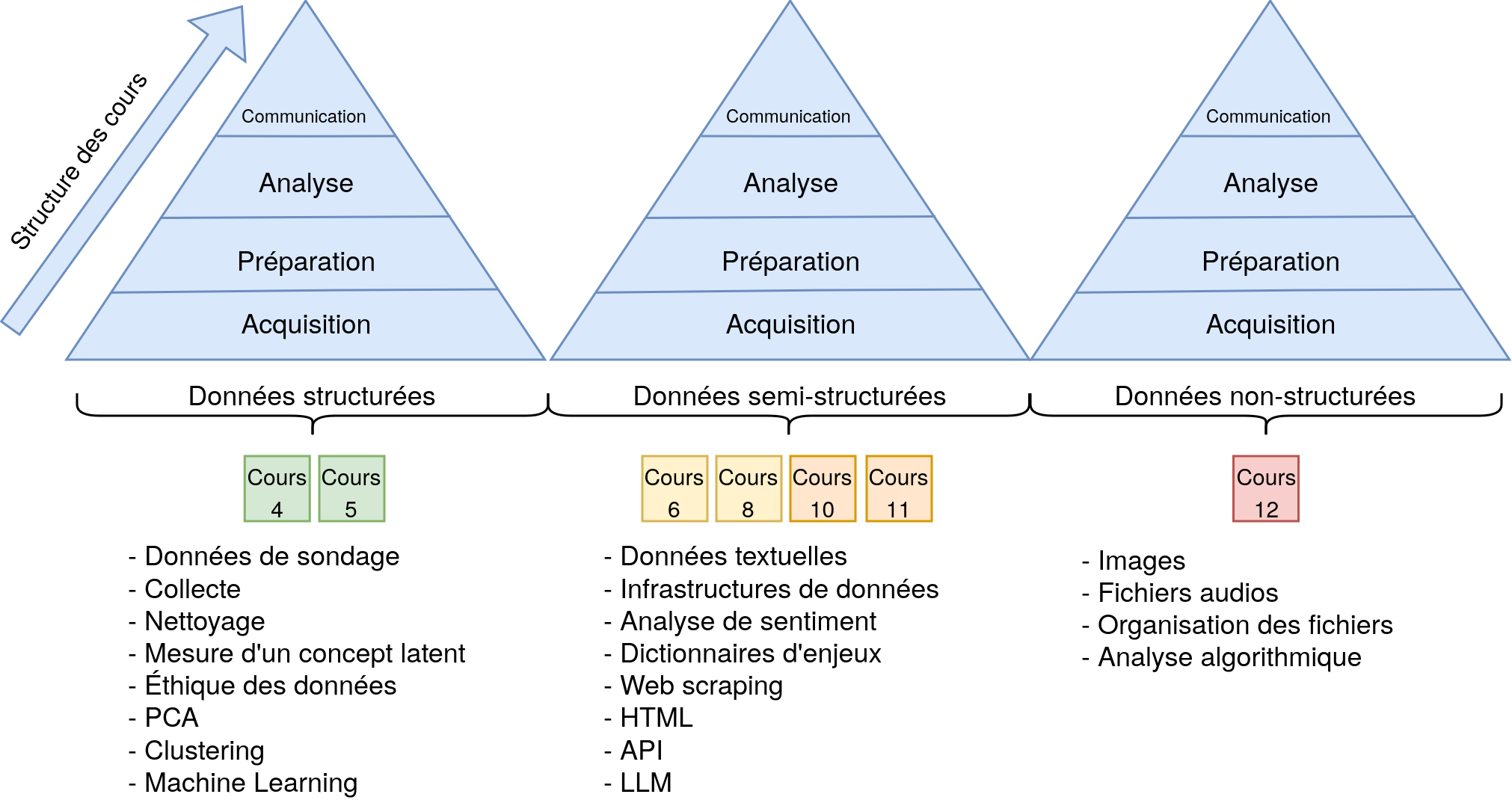
Le fil conducteur du cours
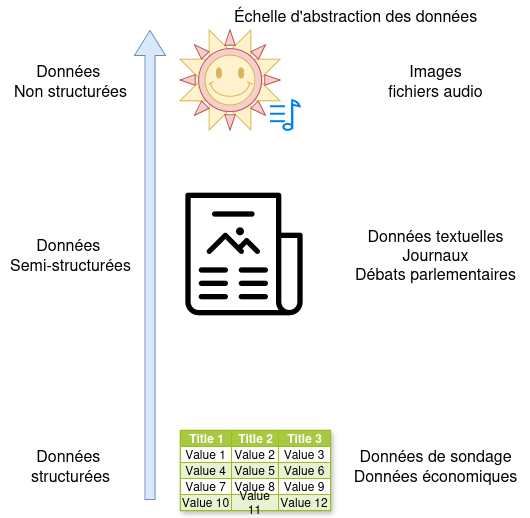
Notre travail cette session a été de transformer des données produites pour d’autres fins en matériel de recherche exploitable.
- observer les données disponibles
- les structurer
- les nettoyer
- les analyser
- interpréter les résultats
La boîte à outils
Produire et analyser
R- Positron
- packages du tidyverse
- visualisation et modèles simples
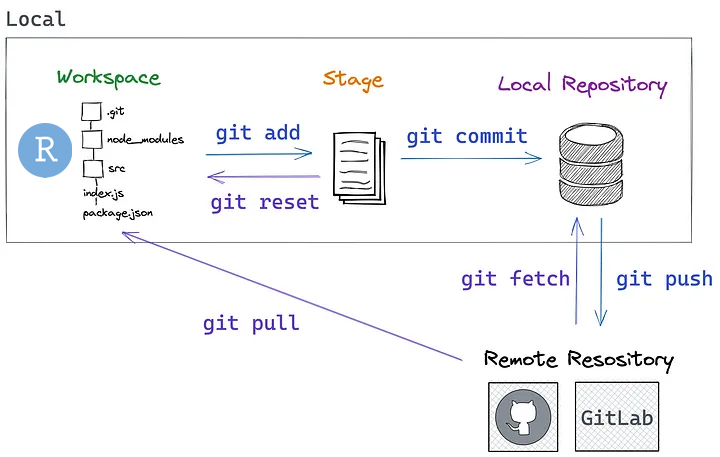
Travailler proprement
- terminal
- Git
- GitHub
- Quarto

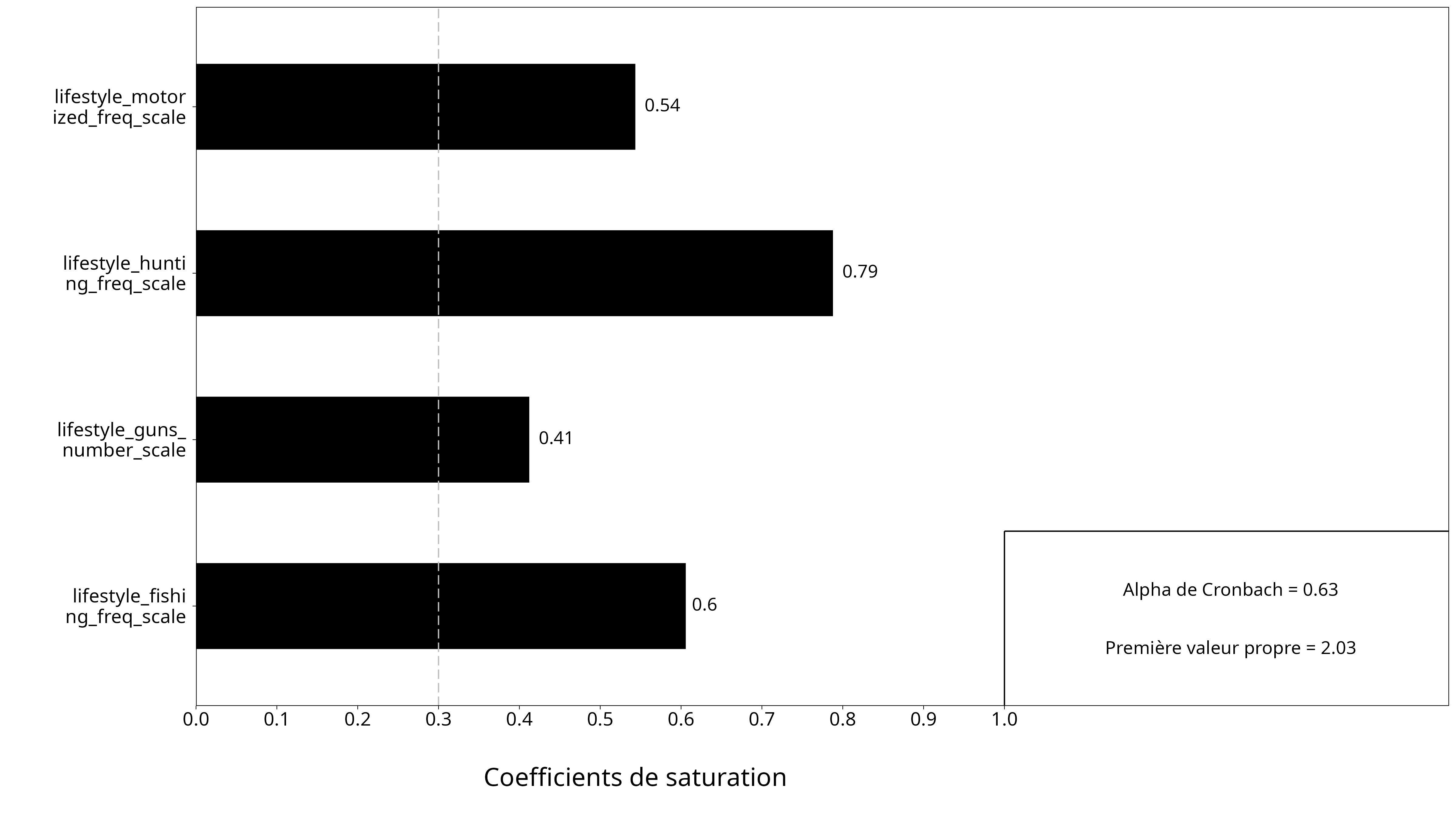
Mesures latentes
- plusieurs concepts importants ne sont pas directement observables
- il faut construire une échelle à partir de plusieurs indicateurs
- une bonne mesure doit être fiable et valide
- l’analyse factorielle aide à voir si les items tiennent ensemble
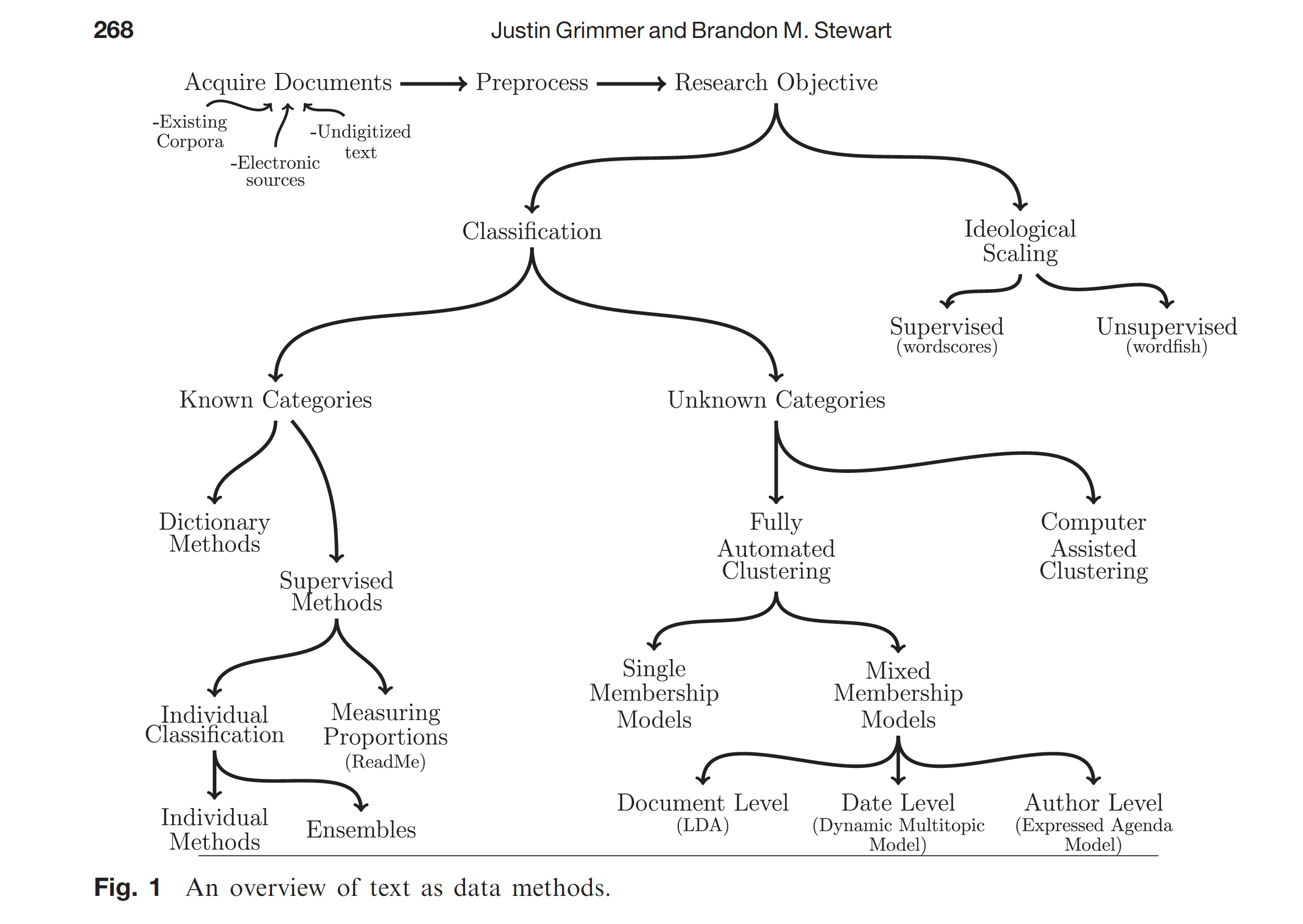
Analyse textuelle
- stopwords
- regex
- dictionnaires
- analyse de sentiment
- classification et résumé
Web scraping
- comprendre la différence entre web et internet
- lire une URL
- distinguer HTML, JSON et APIs
- observer le code source et l’onglet réseau
- extraire, nettoyer puis organiser les données

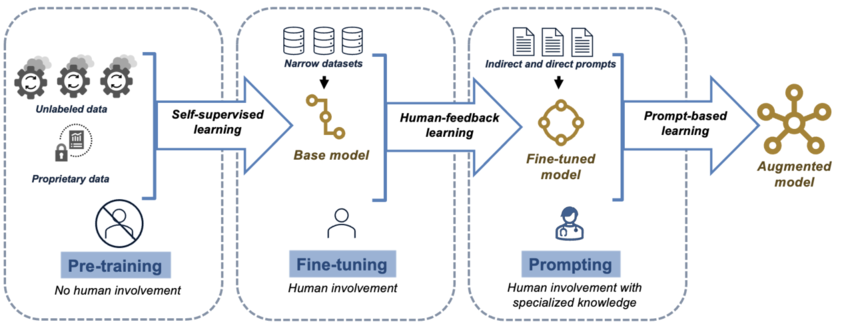
Ce que sont les LLM
- des modèles entraînés sur d’énormes volumes de texte
- utiles pour générer, transformer, classifier et résumer
Mais
- biais des données
- opacité partielle du raisonnement
IA agentique
Un LLM seul produit du texte.
Un agent combine:
- un objectif
- de l’autonomie
- des outils
- des actions observables

MCP
- connecter des outils et des services au modèle
- aller chercher de l’information dans GitHub, Notion, Drive ou le terminal
- passer de la simple conversation à l’exécution de tâches
- ouvrir la porte à des workflows de recherche plus intégrés
